Toto vlákno odkazuje na dvě další vlákna a skvělý článek o této záležitosti. Zdá se, že klasifikace a převzorkování jsou stejně dobré. Používám převzorkování, jak je popsáno níže.
Nezapomeňte, že tréninková sada musí být velká, protože pouze 1% bude charakterizovat vzácnou třídu. Méně než 25 ~ 50 vzorků této třídy bude pravděpodobně problematických. Několik vzorků charakterizujících třídu nevyhnutelně učiní naučený vzor hrubým a méně reprodukovatelným.
RF používá jako výchozí hlasování většiny. Prevalence třídy v tréninkové sadě bude fungovat jako nějaký druh účinného předchozího. Není-li tedy vzácná třída dokonale oddělitelná, je nepravděpodobné, že tato vzácná třída získá při předpovídání většinové hlasování. Místo agregace podle většinového hlasování můžete agregovat hlasovací zlomky.
Ke zvýšení vlivu vzácné třídy lze použít stratifikované vzorkování. To se provádí na nákladech na převzorkování ostatních tříd. Vyrostlé stromy se stanou méně hlubokými, protože je třeba rozdělit mnohem méně vzorků, což omezuje složitost naučeného potenciálního vzoru. Počet pěstovaných stromů by měl být velký, např. 4000 tak, že většina pozorování se účastní několika stromů.
V níže uvedeném příkladu jsem simuloval tréninkovou datovou sadu 5000 vzorků s třídou 3 s prevalencí 1%, 49% a 50%. Bude tedy 50 vzorků třídy 0. První obrázek ukazuje skutečnou třídu tréninkové sady jako funkci dvou proměnných x1 a x2. 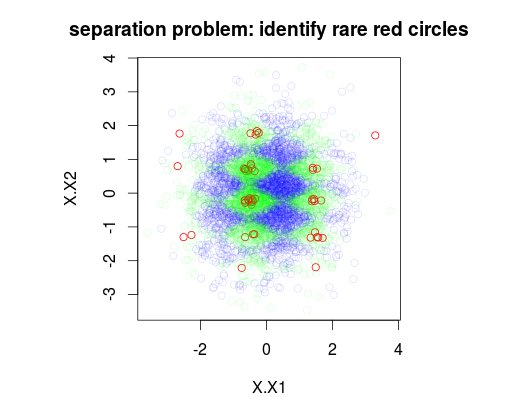
Byly trénovány čtyři modely: výchozí model a tři stratifikované modely s stratifikací tříd 1:10:10 1: 2: 2 a 1: 1: 1. Hlavní, zatímco počet inbagových vzorků (včetně překreslení) v každém stromu bude 5 000, 1050, 250 a 150. Protože nepoužívám většinové hlasování, nemusím vytvářet dokonale vyvážené rozvrstvení. Místo toho by hlasy ve vzácných třídách mohly být váženy 10krát nebo jiným rozhodovacím pravidlem. Vaše cena falešných negativů a falešných poplachů by měla ovlivnit toto pravidlo.
Následující obrázek ukazuje, jak stratifikace ovlivňuje hlasovací zlomky. Všimněte si, že poměr stratifikovaných tříd je vždy těžištěm předpovědí. 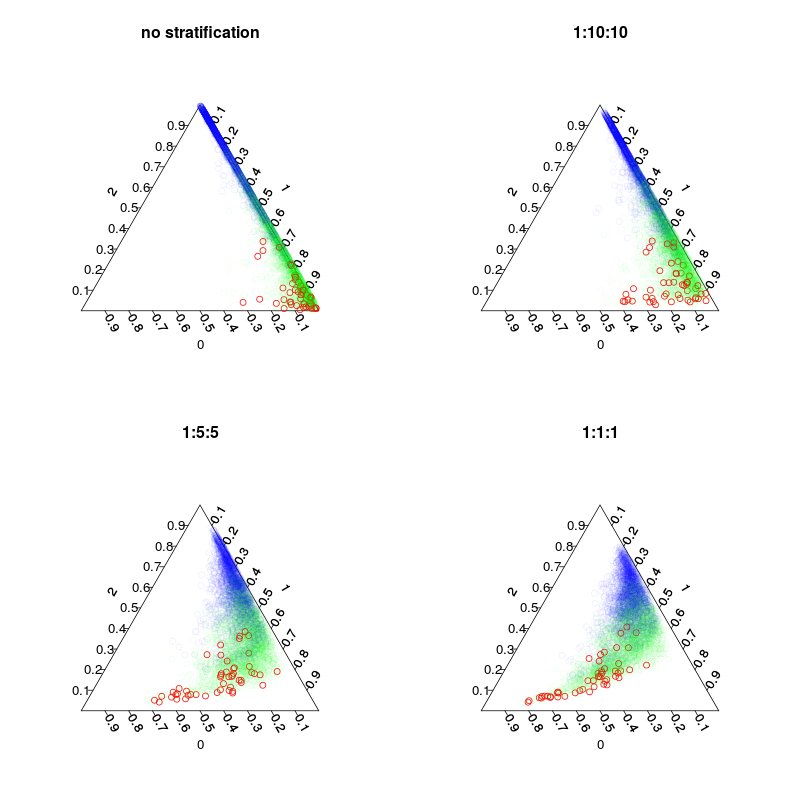
Nakonec můžete použít ROC křivku k nalezení pravidla hlasování, které vám poskytne dobrý kompromis mezi specificitou a citlivostí. Černá čára není stratifikace, červená 1: 5: 5, zelená 1: 2: 2 a modrá 1: 1: 1. Pro tento soubor dat se zdá být nejlepší volbou 1: 2: 2 nebo 1: 1: 1. 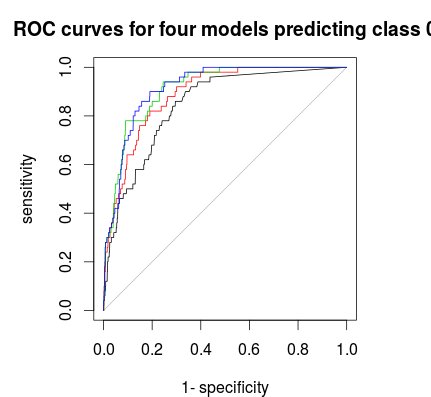
Mimochodem, frakce hlasování jsou zde křížově neplatné.
A kód:
knihovna (plotrix) knihovna (randomForest) knihovna (AUC) make.data = funkce (obs = 5000, vars = 6, noise.factor = .2, smallGroupFraction = .01) {X = data.frame (replicate (vars, rnorm (obs))) yValue = with (X, sin (X1 * pi) + sin (X2 * pi * 2) + rnorm (obs) * noise.factor ) yQuantile = kvantil (yValue, c (smallGroupFraction, .5)) yClass = použít (sapply (yQuantile, funkce (x) x<yValue), 1, součet) yClass = faktor (yClass) tisk (tabulka (yClass)) # pět tříd , první třída má pouze 1% prevalenciData = data.frame (X = X, y = yClass)} plot.separation = function (rf, ...) {triax.plot (rf $ hlasů, ..., col.symbols = c ("# FF0000FF", "# 00FF0010", "# 0000FF10") [as.numeric (rf $ y)])} # vytvořit datovou sadu, kde třída "0" (červené kruhy) jsou vzácnými pozorováními # třída 0 je poněkud oddělitelné od třídy „1“ a zcela oddělitelné od třídy „2 "Data = make.data () par (mfrow = c (1,1)) plot (Data [, 1: 2], main =" problém s oddělením: identifikujte vzácné červené kruhy ", col = c (" # FF0000FF ", "# 00FF0020", "# 0000FF20") [as.numeric (Data $ y)]) # výchozí vlak RF a 10x 30x a 100x převzorkování stratificationrf1 = randomForest (y ~., Data, ntree = 500, sampsize = 5000 ) rf2 = randomForest (y ~., Data, ntree = 4000, sampsize = c (50 500 500), vrstvy = Data $ y) rf3 = randomForest (y ~., Data, ntree = 4000, sampsize = c (50 100 100), vrstvy = Data $ y) rf4 = randomForest (y ~., Data, ntree = 4000, sampsize = c (50,50,50), vrstvy = Data $ y) #plot out-of-bag pluralistické předpovědi (hlasovací zlomky). par (mfrow = c (2,2), mar = c (4,4,3,3))
plot.separation (rf1, main = "bez stratifikace") plot.separation (rf2, main = "1:10:10") plot.separation (rf3, main = "1: 5: 5") plot.separation (rf4 , main = "1: 1: 1") par (mfrow = c (1,1)) plot (roc (rf1 $ hlasů [, 1], faktor (1 * (rf1 $ y == 0))), hlavní = "ROC křivky pro čtyři modely předpovídající třídu 0") graf (roc (rf2 $ hlasy [, 1], faktor (1 * (rf1 $ y == 0))), col = 2, add = T) graf (roc (rf3 $ hlasy [, 1], faktor (1 * (rf1 $ y == 0))), col = 3, add = T) plot (roc (rf4 $ hlasy [, 1], faktor (1 * (rf1 $ y == 0))), col = 4, add = T)