Vím, že toto vlákno je poměrně staré a ostatní odvedli skvělou práci při vysvětlování konceptů, jako jsou místní minima, overfitting atd. Protože však OP hledal alternativní řešení, pokusím se jedním přispět a doufám, že bude více inspirovat zajímavé nápady.
Myšlenkou je nahradit každou váhu w na w + t, kde t je náhodné číslo po Gaussově rozdělení. Konečný výstup sítě je pak průměrným výstupem přes všechny možné hodnoty t. To lze provést analyticky. Poté můžete problém optimalizovat pomocí gradientního klesání nebo LMA nebo jiných optimalizačních metod. Po dokončení optimalizace máte dvě možnosti. Jednou z možností je snížit sigma v Gaussově distribuci a provádět optimalizaci znovu a znovu, dokud sigma nedosáhne 0, pak budete mít lepší místní minimum (ale potenciálně by to mohlo způsobit přeplnění). Další možností je nadále používat ten s náhodným číslem v jeho vahách, obvykle má lepší vlastnost generalizace.
První přístup je optimalizační trik (říkám tomu konvoluční tunelování, protože používá konvoluci přes parametry pro změnu cílové funkce), vyhlazuje povrch krajiny nákladových funkcí a zbavuje se některých místních minim, čímž usnadňuje hledání globálního minima (nebo lepšího lokálního minima).
Druhý přístup souvisí se vstřikováním hluku (na vahách). Všimněte si, že se to provádí analyticky, což znamená, že konečným výsledkem je jedna síť namísto více sítí.
Následující příklady jsou příkladem výstupů pro problém se dvěma spirálami. Síťová architektura je pro všechny tři stejná: existuje pouze jedna skrytá vrstva 30 uzlů a výstupní vrstva je lineární. Použitý optimalizační algoritmus je LMA. Levý obrázek je pro nastavení vanilky; prostřední používá první přístup (jmenovitě opakované snižování sigma směrem k 0); třetí používá sigma = 2.
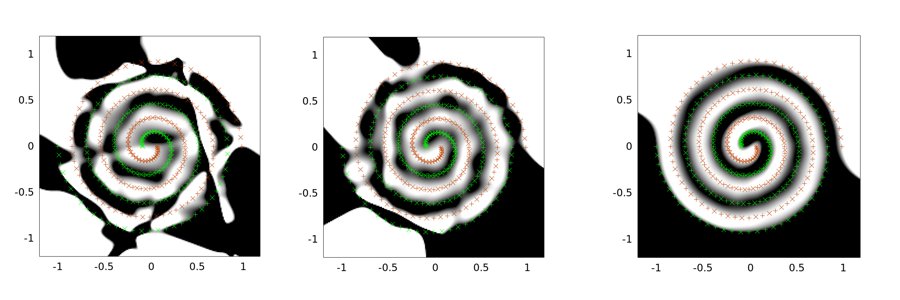
Vidíte, že vanilkové řešení je nejhorší, konvoluční tunelování odvádí lepší práci a vstřikování šumu (s konvolučním tunelováním) je nejlepší (z hlediska vlastnosti generalizace).
Obakonvoluční tunelování a analytický způsob vstřikování hluku jsou mé původní nápady.Možná jsou alternativou, kterou by někdo mohl zajímat.Podrobnosti naleznete v mé práci Kombinace nekonečného počtu neuronových sítí do jedné .Upozornění: Nejsem profesionální akademický spisovatel a příspěvek není recenzován.Pokud máte dotazy k přístupům, které jsem zmínil, zanechte prosím komentář.