Za normálních okolností byste pozorovanou hodnotu nenazvali „odhadovanou hodnotou“.
Navzdory tomu je však pozorovaná hodnota technicky odhad průměru na jeho konkrétním $ x $ a zacházení s ním jako s odhadem nám ve skutečnosti řekne smysl, ve kterém OLS lépe odhaduje průměr.
Obecně řečeno, regrese se používá v situaci, kdy byste měli odebrat další vzorek se stejnými $ x $, nedostali byste stejné hodnoty pro $ y $. V běžné regresi zacházíme s $ x_i $ jako s pevnými / známými veličinami a s odezvami, s $ Y_i $ jako s náhodnými proměnnými (s pozorovanými hodnotami označenými $ y_i $).
Používáme běžnější notaci, píšeme
$$ Y_i = \ alpha + \ beta x_i + \ varepsilon_i $$
Šumový výraz, $ \ varepsilon_i $, je důležitý, protože pozorování nelžou na populační linii (pokud by to udělali, nebyla by potřeba regrese; jakékoli dva body by vám poskytly populační linii); model pro $ Y $ musí počítat s hodnotami, které bere, a v tomto případě distribuce náhodných chybových účtů pro odchylky od ('true') řádku.
Odhad střední hodnoty v bodě $ x_i $ pro běžnou lineární regresi má rozptyl
$$ \ Big (\ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum (x_i- \ bar {x}) ^ 2} \ Big) \, \ sigma ^ 2 $$
, zatímco odhad založený na pozorované hodnotě má rozptyl $ \ sigma ^ 2 $.
Je možné ukázat, že za $ n $ minimálně 3, $ \, \ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum (x_i- \ bar {x}) ^ 2} $ není větší než 1 (ale může být - a v praxi to obvykle je - mnohem menší). [Dále, když odhadnete fit na $ x_i $ podle $ y_i $, také vám zbývá otázka, jak odhadnout $ \ sigma $.]
Ale spíše než sledovat formální demonstraci, přemýšlejte příklad, který, jak doufám, může být více motivující.
Nechť $ v_f = \ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum ( x_i- \ bar {x}) ^ 2} $, faktor, kterým se vynásobí pozorovací rozptyl, aby se získala rozptyl shody na $ x_i $.
Pojďme však pracovat spíše na stupnici relativní standardní chyby než na relativní odchylce (tj. podívejme se na druhou odmocninu této veličiny); intervaly spolehlivosti pro průměr na konkrétním $ x_i $ budou násobkem $ \ sqrt {v_f} $.
Takže k příkladu. Vezměme si data cars v R; toto je 50 pozorování shromážděných ve 20. letech 20. století ohledně rychlosti automobilů a ujetých vzdáleností:
Jak tedy hodnoty $ \ sqrt {v_f} $ porovnat s 1? Takhle:
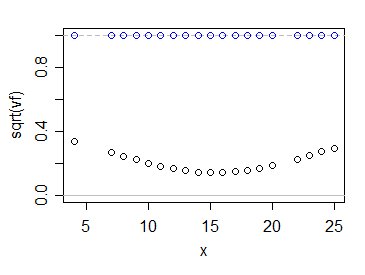
Modré kruhy zobrazují násobky $ \ sigma $ pro váš odhad, zatímco černé kruhy pro obvyklý odhad nejmenších čtverců. Jak vidíte, použití informací ze všech dat činí naši nejistotu ohledně toho, kde střední hodnota populace leží, podstatně menší - alespoň v tomto případě a samozřejmě za předpokladu, že lineární model je správný.
Výsledkem je , pokud vyneseme (řekněme) 95% interval spolehlivosti pro průměr pro každou hodnotu $ x $ (včetně na jiných místech než pozorování), jsou limity intervalu na různých $ x $ obvykle malé ve srovnání s variace v datech:
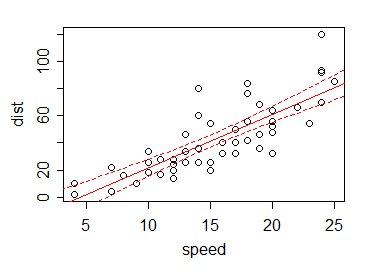
Toto je výhoda „vypůjčení“ informací z jiných hodnot dat, než je současná.
Ve skutečnosti můžeme použít informace z jiných hodnot - prostřednictvím lineárního vztahu - k získání dobrých odhadů hodnoty na místech, kde nemáme ani data. Vezměte v úvahu, že v našem příkladu nejsou žádná data na x = 5, 6 nebo 21. S navrhovaným odhadem tam nemáme žádné informace - ale s regresní přímkou můžeme nejen odhadnout průměr v těchto bodech (a na 5,5 a 12,8 a atd.), můžeme k tomu uvést interval - opět však takový, který se spoléhá na vhodnost předpokladů linearity (a konstantní variance $ Y $ s a nezávislost).